{kind=link}
{kind=link}
{kind=link}
{kind=link}
Document Actions
ZUCCARO
Ein modernes, konfigurierbares Informationssystem für die Geisteswissenschaften
Martin Raspe
Forschung ohne Computer – das ist mittlerweile undenkbar. Auch Geisteswissenschaftler setzen den Rechner nicht mehr nur zum Abfassen von Texten ein. Längst spielen Datenbanken, graphische Bildverarbeitung und das Internet eine wichtige Rolle in der kunsthistorischen Forschung.
ZUCCARO ist ein umfangreiches Software-Projekt der Bibliotheca Hertziana, dem Max-Planck-Institut für Kunstgeschichte in Rom. Der Name ist nicht nur ein Akronym, sondern bezieht sich auch auf den italienischen Maler und Kunsttheoretiker Federico Zuccari (1542-1609), dessen Haus auf dem Pincio-Hügel, unweit der Spanischen Treppe, heute Sitz des Institutes ist. Das „redende“ Wappensymbol des Künstlers, der Zuckerhut, ist zugleich das Signet der Bibliothek. Die Büchersammlung des Instituts ist mit über 254.000 Bänden eine der umfangreichsten Bibliotheken zur italienischen Kunstgeschichte und dient einem internationalen Publikum als Arbeitsinstrument. Sie bietet ideale Voraussetzungen zur Erforschung der römischen Kunst und ist zugleich ein Ort des wissenschaftlichen Austausches im Herzen Roms. Daneben existiert eine Fotothek mit einem Bestand von ca. 742.000 Fotografien, 100.000 Negativen und bereits über 20.000 hoch auflösenden Scans. Neben kompletten Fotoarchiven enthält sie bedeutende Schenkungen und Nachlässe, darunter jene von Richard Krautheimer und Hanno-Walter Kruft, sowie das Gernsheim Corpus of Drawings.
ZUCCARO ist gedacht als Zusammenfassung mehrerer einzelner EDV-Unternehmungen des Instituts. Um das Konzept zu erläutern, ist daher ein kurzer Rückblick auf die Vorgeschichte notwendig. Wissenschaftliche Daten werden in der Hertziana schon seit über einem Jahrzehnt gesammelt, vor allem in Form des elektronischen Bibliothekskataloges (OPAC) auf der Basis des Systems allegro/avanti. Hinzu kommen die wissenschaftlichen Daten zu den neu erworbenen Fotografien, die seit längerem in enger Zusammenarbeit mit dem Bildarchiv Foto Marburg mit Hilfe des Datenbanksystems HIDA-MIDAS aufgenommen werden und über den Marburger Server abgerufen werden können.
Auch Forschungsdaten werden in der Hertziana schon seit längerer Zeit elektronisch gesammelt. Der digitale „Census of Antique Works of Art and Architecture Known in the Renaissance” ist ein ambitioniertes Datenbankprojekt, dem ZUCCARO zahlreiche Anregungen schuldet. Die Datenbank wurde 1981 von Arnold Nesselrath ins Leben gerufen. Sie ist die elektronische Umsetzung einer bereits 1946 am Londoner Warburg Institute begonnen Unternehmung, die erhaltenen Informationen zum Studium der Antike in der Renaissancezeit zu sammeln und zu verknüpfen. Der Census beinhaltet sowohl Daten zu den in der frühen Neuzeit angefertigten Dokumenten als auch zu den betreffenden antiken Monumenten.
Seit dem Jahr 2000 plant das Institut auch, wissenschaftliche Daten aus Forschungsprojekten in elektronischer Form zu speichern und zugänglich zu machen. Ein Forschungsschwerpunkt des Hauses ist die Geschichte der italienischen Architektur der Neuzeit, insbesondere der Renaissance und des Barock. Dabei kommt der Dokumentation von Architekturzeichnungen besondere Bedeutung zu, den in ihnen wird der künstlerische Schaffensprozess sichtbar. Historische Architekturzeichnungen sind Planungsdokumente, eigenständige Kunstwerke und zugleich Kommunikationsmittel zwischen Bauherrn und Architekten. Leider sind sie fragil und lichtempfindlich, werden unter Verschluss gehalten und sind deshalb oft nicht gut erforscht. Zusammengehörendes Material ist nicht selten verstreut und weit vom ausgeführten Bauwerk entfernt aufbewahrt.
Um diese Situation zu verbessern, wurde unter der Leitung von Elisabeth Kieven die Forschungsdatenbank „Lineamenta“ ins Leben gerufen. Sie will Architekturzeichnungen wissenschaftlich erschließen, online zugänglich machen und dadurch neue Forschungen ermöglichen. Ausgehend vom 17. und 18. Jahrhundert in Italien wird nicht nur das Material selbst gesammelt, sondern auch Nachrichten zu Personen, Institutionen, Bauten und Projekten sowie Schriftquellen und Forschungsliteratur. Hochauflösende Scans ermöglichen das Studium der Zeichnungen am Bildschirm in bisher unbekannter Genauigkeit und Intensität. Zahlreiche Zeichnungssammlungen sind bereits in Lineamenta vertreten.
Parallel dazu wird unter Leitung von Sybille Ebert-Schifferer die Forschungsdatenbank „ArsRoma“ zur römischen Malerei der Barockzeit konzipiert. Sie erfasst systematisch die Kunstproduktion in Rom zwischen 1580 und 1630. Das Projekt konzentriert sich sowohl auf das gesellschaftliche Umfeld als auch auf die stilistischen Ausprägungen der Bildwerke. Neben Bildwerken und Werkgruppen werden Daten zu Künstlern, Auftraggebern, Sammlern, Beratern und Literaten dieser Zeit aufgenommen. Hinzu kommen auch Personengruppen, etwa die römischen Bruderschaften, Akademien und Orden, sowie die verzweigten Familien mit ihren Sammlungen. Auch ihre Beziehungen untereinander und zu Künstlern sollen abgebildet werden. So werden neue Aspekte der Künstler-, Sammlungs-, Stil-, Sozial-, Religions- und Wirtschaftsgeschichte im Kontext der Entwicklung der römischen Barockmalerei sichtbar gemacht. Ein weiteres Ziel ist die Verknüpfung formaler Motive wie Posen, Gesten und Physiognomik mit ihren möglichen künstlerischen Vorbildern. Mit Hilfe der Datenbank sollen Migrationen und Traditionen erfolgreicher Modelle und visuelle Kanonbildungen verfolgt werden und die gesellschaftlichen Mechanismen, die zur Herausbildung stilistischer Präferenzen führen, aufgezeigt werden.
Um die beiden Datenbanken nicht unabhängig voneinander aufbauen zu müssen und zugleich die vorhandenen Daten zu nutzen, kam der Gedanke auf, eine gemeinsames Framework zu schaffen, von dem beide Projekte profitieren. ZUCCARO ist der Versuch, mit elektronischen Mitteln die heterogenen EDV-gestützten Datensammlungen miteinander so zu verbinden, dass
- sie über ein gemeinsames Interface benutzt werden können
- sie Stammdaten, etwa zu Personen und topographischen Angaben, gemeinsam nutzen
- neue und externe Forschungsdatenbanken leichter eingebunden werden können
- ein komplexes, integriertes Informationssystem als Forschungsinstrument entsteht.
Um diese Ziele zu verwirklichen, war es notwendig, ein neuartiges, umfassendes Datenmodell zu konzipieren, das diese Aufgaben erfüllen kann, und die dazu erforderliche Software zu erstellen. Dieses Projekt soll im Folgenden vorgestellt werden.
Bestehende kunsthistorische Datenbanken
Größere kunsthistorische Datenbank-Unternehmungen hat es in der Vergangenheit schon gegeben. Vom "Census" war oben bereits die Rede. Die seinerzeit für dieses Pilotprojekt verwendete Software ist leider heutzutage veraltet, eine Modernisierung derzeit nicht in Sicht. Außerdem werden die jahrelang mit öffentlichen Finanzmitteln zusammengetragenen Daten kommerziell verwertet und können nur gegen eine nicht unbeträchtliche Lizenzgebühr eingesehen werden.
Auch das bereits erwähnte Datenbanksystem HIDA (Historischer Dokument-Administrator) mit dem von Lutz Heusinger in Marburg erarbeiteten und formal definierten kunsthistorischen Datenmodell MIDAS krankt an ähnlichen Einschränkungen. Zwar wird die Software noch weiterentwickelt, die interne Datenstruktur und die Indexierungsmechanismen entsprechen jedoch nicht den heute gültigen Regeln zur Normalisierung von relational verknüpften Datenbeständen und müssten dementsprechend redigiert und neu strukturiert werden. Hinsichtlich der Komplexität des Datenmodells, das möglichst alle relevanten kunsthistorischen Sachfragen abbilden will, ist das System zukunftsweisend gewesen. Im Aufbau ähnelt die Datenstruktur bereits dem heute als Standard verwendeten XML-Format. Dadurch können die mit HIDA-MIDAS erfassten Daten leicht exportiert und in heute nutzbare Formate konvertiert werden. Komplexe Abfragen über den Datenbestand und eine universelle Nutzung über das Internet sind jedoch nur eingeschränkt möglich. Die notwendige Software ist kostspielig, schwierig zu installieren und zu bedienen, so dass sich das Marburger System nicht so weit durchgesetzt hat, wie es wünschenswert gewesen wäre.
Ähnliches gilt für das von Manfred Thaller entwickelte Datenbanksystem „Kleio“, das vor allem in den historischen Disziplinen, aber auch in dem kunsthistorischen Projekt einer Verbund-Diathek „Prometheus“ Verwendung findet. Auch hier ist eine anspruchsvolle proprietäre Software entstanden, die im Prinzip sehr leistungsfähig, aber hoch kompliziert und nur spärlich dokumentiert ist. Die daraus resultierende Abhängigkeit von der technischen Betreuung durch den Entwickler ist leider ein Hindernis für die Verbreitung des Systems.
Aus diesen Erfahrungen versucht die Bibliotheca Hertziana zu lernen und den mittlerweile beträchtlich fortgeschrittenen Stand der Technik zu nutzen, um solche Probleme zu vermeiden.
Fertiglösung oder Eigenentwicklung?
Im Rahmen des Projekts Lineamenta wurde zunächst geprüft, ob man vorhandene kommerzielle Software übernehmen und gegebenenfalls ausbauen oder weiterentwickeln lassen könne. Zur Debatte standen Programme zur Inventarisierung von Fotosammlungen, wie das von der Diathek der Berliner Humboldt-Universität verwendete Programm „Imago“, und verschiedene auf den Museumsbereich zugeschnittene Software. Es stellte sich aber heraus, dass ähnliche Probleme wie die oben geschilderten vorhersehbar sind, wenn man sich von einem kommerziellen Produkt und dessen Entwicklern abhängig macht. Zudem haben professionelle Softwarefirmen wenig Interesse daran, komplexe Datenbanksysteme zu entwickeln, die kaum gewinnbringend vermarktet werden können, da sie nur für eine vergleichsweise geringe Anzahl von Spezialprojekte eingesetzt werden kann.
Die Ergebnisse der Vorüberlegungen lassen sich zusammenfassen: Für eine komplexe geisteswissenschaftliche Datenbankanwendung kommt man zur Zeit um eine Eigenentwicklung nicht herum. Die vorhandene Software ist entweder veraltet oder proprietär und dadurch unflexibel und nicht zukunftssicher. Eine geisteswissenschaftliche Standardlösung auf dem modernen Stand der Technik gibt es nicht. Neu zu entwickelnde Software muss als „open source“ vorliegen, der unkompilierte Quelltext und auch die Rechte daran müssen dem Institut zur freien Verfügung stehen, um später Änderungen oder Erweiterungen vornehmen zu lassen, auch wenn die Entwickler nicht mehr zur Verfügung stehen.
Datenmodell
Für eine Forschungsdatenbank ist außerdem wichtig, dass sie sich nicht allein zur Erfassung und Dokumentation von Kunstwerken eignet, sondern darüber hinaus Fragen der Forschung unterstützt oder ermöglicht. Einfache Recherchen nach Primärmerkmalen wie in einem Museumsinventar reichen nicht aus. Es sollen vielmehr auch Bezüge unterschiedlicher Art zwischen den einzelnen in der Datenbank gespeicherten Objekten, Personen und Orten abgebildet und sichtbar werden, insbesondere die historischen Beziehungen, die dem Faktor Zeit unterworfen sind. Der Bestand soll nach Kombinationen von Merkmalen und zeitlichen Einschränkungen durchsucht werden können, auch statistische Fragen sollen mögliche sein, etwa nach der Häufigkeit bestimmter Merkmale oder nach deren topographischer Verteilung.
Bei der Konzeption stand zunächst die Datenmodellierung im Vordergrund. Nach dem Vorbild des „Guide to the Description of Architectural Drawings“ des Getty-Instituts wurde ein erster Entwurf eines Datenformulars für Architekturzeichnungen erarbeitet. Die Getty-Richtlinien erwiesen sich dabei als teilweise unnötig komplex, teilweise aber auch nicht ausreichend für die Beschreibung des historischen Umfelds der Zeichnungen. Nach und nach entstand ein verzweigtes Datenmodell für alle zu erfassenden Datentypen, das in einem „Pflichtenheft“ festgehalten wurde. Die Diskussionen wurden in einer Arbeitsgrppe geführt, der Costanza Caraffa, Michael Eichberg, Johannes Röll, Georg Schelbert, Antje Scherner und Hermann Schlimme angehörten. In der Folgezeit stellten Hannah Baader, Peter Hemmer und Golo Maurer ähnliche Überlegungen für ArsRoma an.
Die beiden Datenmodelle, die im Laufe der Zeit immer detaillierter ausgearbeitet wurden, liegen auch dem jetzigen Konzept, das unten erläutert wird, noch zu Grunde.
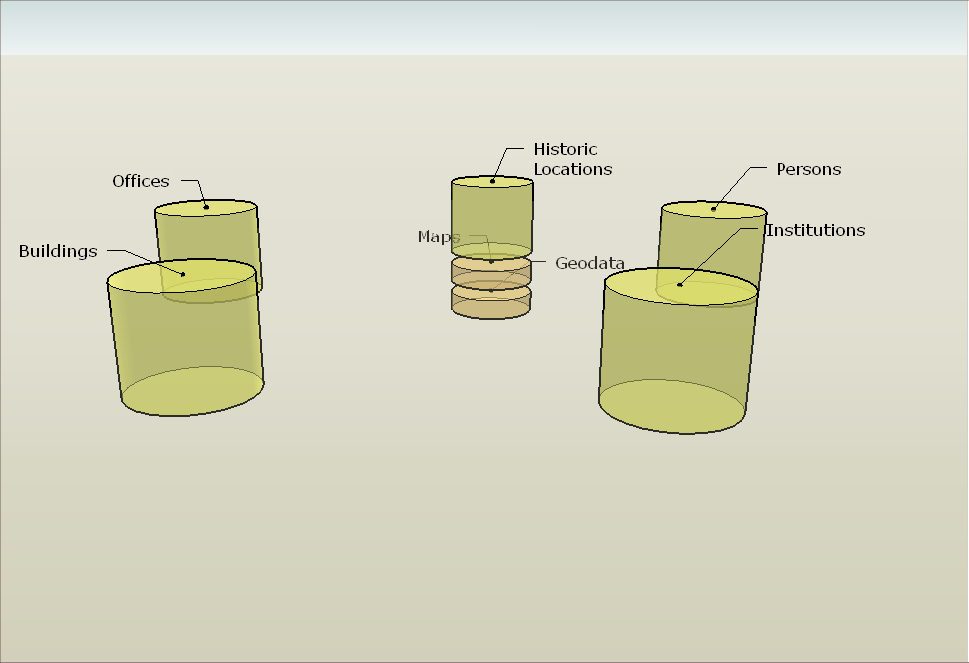
Die Konzeption des Datenmodells hat im Laufe der Beschäftigung mit ZUCCARO zahlreiche Veränderungen durchlaufen, nicht zuletzt als Reaktion auf das Bekanntwerden neuer softwaretechnischer Möglichkeiten. Den Kernbereich bilden die Stammdaten, die von allen Forschungsprojekten gemeinsam genutzt werden sollen und im Institut kontinuierlich gesammelt werden bzw. bereits vorhanden sind. Folgende Kategorien sind hier vorgesehen:
- Person (vorrangig Künstler, daneben aber auch Auftraggeber und andere für den geschichtlichen Kontext wichtige Personen)
- Institution (darunter fallen auch klarumrissene soziale Personengruppen)
- Amt (historische Funktionen, die von jeweils einer Person bekleidet wurde)
- Historisch-topographischer Ort (darunter fallen auch historische Verwaltungseinheiten und Territorien)
- Bauwerk (sowohl architekturgeschichtlich als auch topographisch verstanden)
Zu diesem sozial-topographischen Datennetz kommen dann die eigentlich kunsthistorischen Kategorien hinzu. Die Basiskategorie bildet hier das allgemeine Kunstobjekt, von dem die Kunstgattungen abgeleitet werden. Allen Kunstobjekten gemeinsam sind Angaben zur Technik, zu den Maßen, zur Ikonographie, zum Erhaltungszustand. Sie werden von den abgeleiteten Datenklassen „ererbt“. Diese sind:
- Gemälde
- Skulptur
- Einzelblatt (das Papier als materielle Grundlage einer Zeichnung)
- Druckgraphik
- Historische Karte
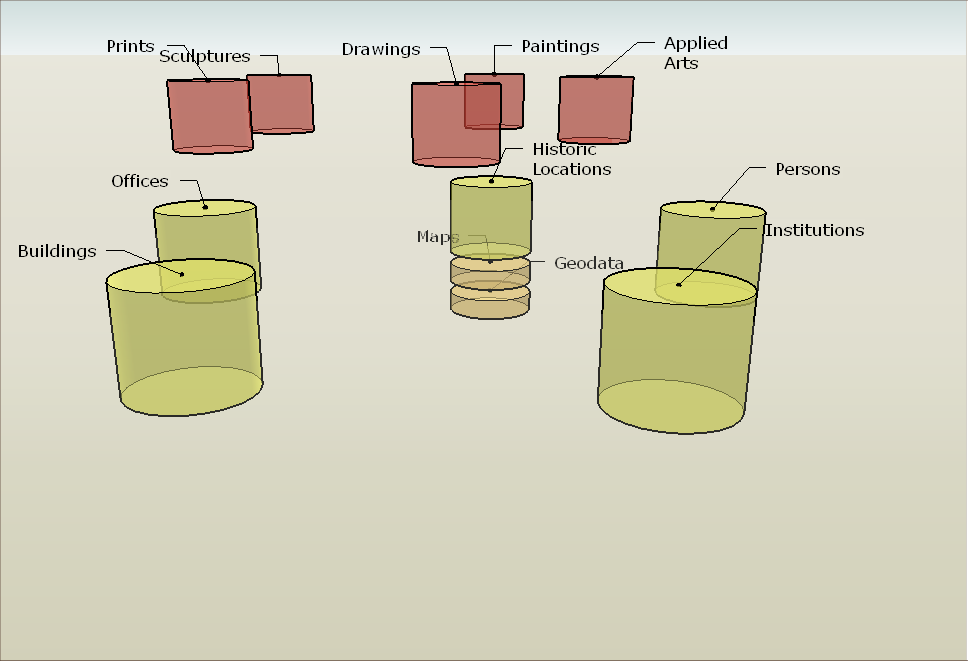
Weitere Datenklassen wie Kunsthandwerkliches Erzeugnis, Foto, Film sind vorgesehen, werden aber in der derzeitigen Form noch nicht umgesetzt. Für das Projekt Lineamenta ist die Zeichnung, speziell die Architekturzeichnung besonders interessant. Daher werden hier die Angaben besonders detailliert aufgeschlüsselt. Jede Zeichnung kann eine Anzahl von Komponenten enthalten, die in einzelnen Objektklassen beschrieben werden. Es handelt sich um:
- Zeichnung (auf einem Blatt können Zeichnungen mehrerer Künstler vorkommen)
- Beschriftung
- Maßstabskala
- Stempel oder Sammlermarke
- gezeichnete Rahmung
Den Forschungsinteressen von ArsRoma zum Kontext der Bilder tragen weitere Kategorien Rechnung: Die Kunstsammlung und der Bilderzyklus, die als „container“ historische Zusammenstellungen von Kunstwerken repräsentieren; außerdem wird es spezielle Klassen zur Beschreibung von motivischen Merkmalen wie Gestik und Mimik geben.
An jedes Datenobjekt lassen sich „Metadaten“ anhängen, in denen die wissenschaftliche Information verwaltet wird:
- Archivalien und andere Primärquellen
- Bibliographische Angaben (mit Verknüpfungen zu Bibliothekskatalogen)
- Internet-Verknüpfungen (hyperlink)
- Bildinformationen (Fotografien, Scans und die zugehörigen technischen Daten)
- Wissenschaftlicherr Kommentar (kann auch von angemeldeten Benutzern hinzugefügt werden)
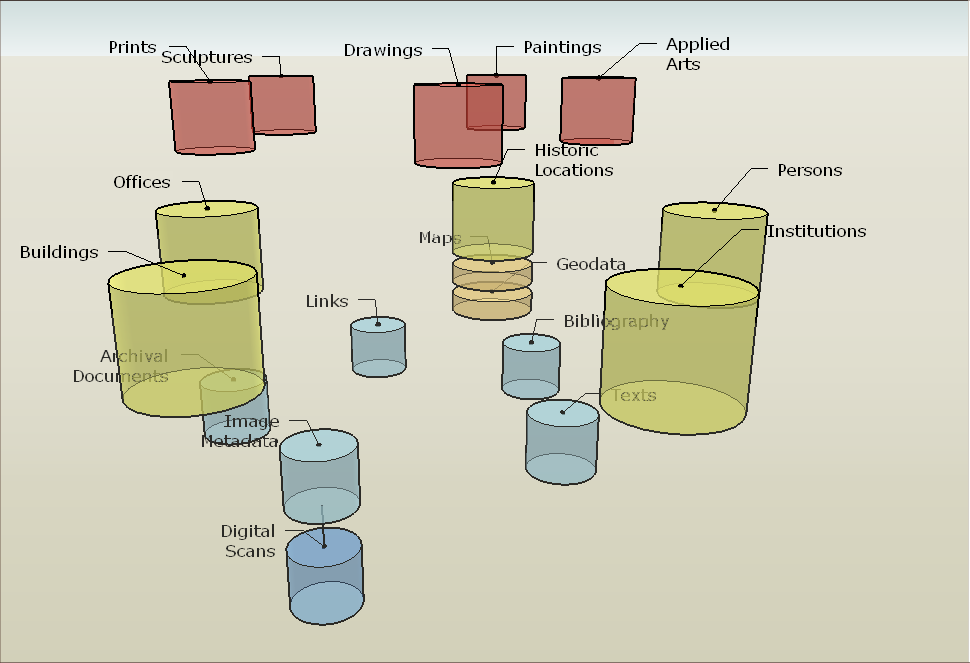
Die meisten dieser Klassen können durch ein Typ-Feld weiter kategorisiert werden, in das ein Wert aus einem kontrollierten, hierarchisch strukturiertes Vokabular (mehsprachig angelegt im VDEX-Format) eingetragen werden kann.
Beziehungen
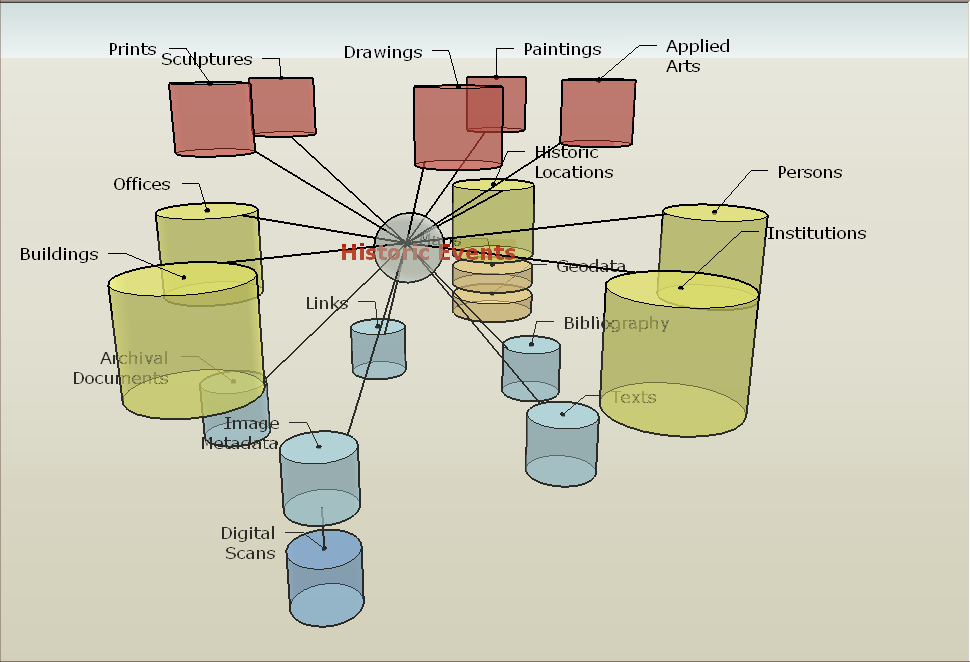
In den Beziehungen zwischen den Datenobjekten liegt die eigentliche konzeptionelle und technische Neuerung von ZUCCARO. Eine geisteswissenschaftliche Datenbank versucht immer, im digitalen Objekt Gegenstände und Konzepte der wirklichen Welt abzubilden. Viele der Merkmale dieser Objekte, die herkömmlicherweise wie auf Karteikarten in Formularfeldern eingetragen werden, lassen sich aber sinnvoller als Beziehungen zwischen verschiedenen Objekten darstellen. So ist zum Beispiel der Zeichner eines architektonischen Entwurfs im Grunde kein Merkmal desselben, vielmehr gab es in der Vergangenheit eine Beziehung zwischen der Person des Künstlers und dem Blatt Papier: Zu einem konkreten historischen Zeitpunkt zeichnete er einen Grundriss darauf. Auch andere historische Personen traten in Beziehung zu dem Blatt: Der Auftraggeber begutachtete es und lehnte es vielleicht ab, der Sohn des Zeichners erbte es, ein Sammler kaufte es, ein Museum stellte es aus. Ebenso stand die Zeichnung in Beziehung zu verschiedenen Orten, an denen es sich befand oder für die sie gedacht war.
Der eigentliche historische Sachverhalt drückt sich also nicht in Merkmalen, sondern in Beziehungen aus, die in der Regel als Ereignisse beschrieben werden können. Das Ereignis fand zu einem konkreten historischen Zeitpunkt statt, der nicht immer genau bekannt und oft nur als wahrscheinlich angenommen wird. Daher haben wir uns entschlossen, die vermeintlichen Merkmale der Gegenstände in historische Beziehungen aufzulösen und jede dieser Beziehungen durch ein eigenes Objekt zu beschreiben, das wir „Ereignis“ nennen.
Zwischen zwei historischen Gegenständen können unterschiedliche, aber nicht beliebige Ereignis-Beziehungen bestehen: Eine Person kann eine Zeichnung zeichnen oder kaufen, aber nicht heiraten. Daher werden die Beziehungsmöglichkeiten zwischen jeweils zwei Objektklassen auf die zulässigen Typen eingeschränkt, die wiederum in einem wohldefinierten – gegebenenfalls auch erweiterbaren – Vokabular festgelegt sind. So wird die Dateneingabe abgesichert und zugleich eine Recherche nach Beziehungstypen möglich. Oft sind nicht beliebig viele Beziehungen einer Art zwischen zwei Objekten möglich oder sinnvoll: Eine Person wird nur einmal an einem Ort geboren. Auch solche Beschränkungen der „Multiplizität“ können im Datenmodell angegeben werden. An das Ereignisobjekt können zudem, wie oben beschrieben, Metadaten (Bibliographie, Bilder, Kommentare usw.) angehängt werden, so dass jedes Ereignis genau wie ein konkreter Gegenstand wissenschaftlich adäquat dokumentiert wird.
Die Datenmodellierung durch Beziehungen ist unter anderem angeregt durch das Conceptual Reference Model (CRM) des CIDOC (Comité international pour la documentation du Conseil international des musées). Hier ist ein sehr weitreichendes Modell zur Klassifikation von Kultur entstanden, von dem wir uns haben anregen lassen, auch wenn wir keine vollständige Umsetzung anstreben. Diese Sichtweise erscheint zunächst ungewohnt; sie verlangt dem wissenschaftlichen Bearbeiter wie dem Benutzer einiges Umdenken ab. Ein erster, modellhafter Prototyp, den Georg Schelbert mit Hilfe eines relationalen Datenbanksystems (Filemaker) umgesetzt hat, zeigt, dass der Weg gangbar ist (Datenbank Zuccaro: http://fm.biblhertz.it/html/zucc_start.htm). Neue Daten für das Projekt Lineamenta werden inzwischen damit aufgenommen. Dabei zeigt sich schon jetzt, dass bei genügender Datendichte ungewohnte Perspektiven auf das Material entstehen, die neue Fragestellungen anregen und neue Einsichten erlauben.
Software-Implementation
Bei der Suche nach einer geeigneten Software-Basis kamen zunächst so genannte Content-Management-Systeme (CMS) in den Blick. Dies sind Softwarelösungen, die eine Vielzahl von unterschiedlichen Inhaltstypen (Dokumenten) verwalten und im Internet publizieren können. Sie verfügen über differenzierte Administrations- und Redaktionsverfahren, bei denen die Benutzer entsprechend ihrer Aufgabe Zugriffs- und Bearbeitungsrechte erhalten. Die Dokumente werden in festgelegten Arbeitsabläufen (workflows) erstellt. In der Regel gehört ein Datenbanksystem dazu, das die Dokumente speichert und erschließt.
Die Wahl fiel auf ZOPE, ein Web-Applikationsserver, der sich durch große Flexibilität und Erweiterbarkeit auszeichnet. Mit diesem System wurde bereits die erste Version von Lineamenta erstellt, die der differenzierten Erfassung von Architekturzeichnungen diente. Mit Hilfe verschiedener neu zu erstellender Module sollte das Datenmodell in die Architektur des auf ZOPE basierenden CMS "Plone" integriert werden. Im Laufe der Arbeiten stellte sich jedoch heraus, dass die zu leistenden Anpassungs- und Erweiterungsarbeiten zu umfangreich wurden und die objektorientierte ZOPE-Datenbank sich für das komplexe Datenmodell im Grunde nicht speziell eignete.
Die technologischen Fortschritte im Bereich des "Semantic Web" und der "Open Linked Data" haben uns bewogen, einen neuen Weg einzuschlagen. Für die hochgradig atomisierten und durch vielfältige Beziehungen (Relationships) miteinander verknüpften Daten sind andere Datenbank-Konzepte besser geeignet.
Mit der nativen XML-Datenbank "eXist" hat die Hertziana bereits in zahlreichen anderen Projekten gute Erfahrungen gemacht. Das System ist mittlerweile so ausgereift, daß es auch als Web-Frontend und Apllikations-Server in Frage kommt.
Das Datenmodell wird in der Ontologie-Sprache OWL neu formuliert, damit es leichter zu handhaben ist. Viele Bereiche der Anwendung (Formulare, Abfragemodule, mehrsprachige Oberflächen) sollen aus dem OWL-Modell generiert werden.
Als Backend zur Speicherung der Daten ist derzeit eine Graphdatenbank vorgesehen, in der sich das auf Beziehungen beruhende Datenmodell besonders gut abbilden läßt. Das System "Neo4j" bietet sich dabei besonders an; es ist in Java geschrieben und läßt sich über eine REST-Schnittstelle und mit Hilfe der Abfragesprache "Cypher" vielseitig und schnell ansprechen. Es eignet sich gleichermaßen gut zur Eingabe, zur Editierung und zur Abfrage von Daten, die auf "Graphen" beruhen, also auf gerichteten Verkettungen von Datenobjekten (nodes) und Beziehungen (relationships). Im Dezember wird die Version 2.0 erscheinen. Ein baldiger Umstieg auf ein neues System ist auch deswegen erforderlich, weil die proprietäre Software "Filemaker" mit der nächsten Version die mit XSLT produzierte Webansichten nicht mehr unterstützt, die für Zuccaro einen wesentlichen Bestandteil darstellen.
Weitere Komponenten
Kurz erwähnt seien weitere Komponenten und digitale Werkzeuge, die bereits im Institut Verwendung finden und auf lange Sicht in ZUCCARO integriert werden sollen. Vom OPAC (Online-Katalog) der Bibliothek und von den Foto-Daten der Fotothek war bereits die Rede.
Für Forschungen zur Kunstgeschichte Roms sind die historischen Stadtpläne, besonders seit dem 16. Jahrhundert, ein unverzichtbares Quellenmaterial. Georg Schelbert sammelt und katalogisiert sie in der Datenbank CIPRO (Catalogo Illustrato delle Piante di Roma). In ZUCCARO sollen die Pläne darüber hinaus als Rechercheinstrument und als Darstellungsmedium genutzt werden. Durch interaktive Suche auf dem Stadtplan und Anklicken des hervorgehobenen Monuments gelangt der Benutzer direkt zu den Informationen über den Gegenstand. Zugleich sollen Ergebnisse zu Suchabfragen, etwa zu Bauwerken mit bestimmten Merkmalen, visuell auf dem Stadtplan angezeigt werden, so dass topographische Häufungen oder Zusammenhänge umittelbar erkennbar werden.
Auf lange Sicht ist auch geplant, GIS (Geo-Informationssystem)-Funktionen in ZUCCARO zu integrieren. Alle ortsgebundenen Objekte sollen durch ihre Geo-Koordinaten identifiziert werden. Auf diese Weise sind zum Beispiel Suchen innerhalb der Grenzen historischer Territorien denkbar. Ein solches Gebiet wird als Koordinaten-Polygon abgebildet, das in einer gewissen Zeitspanne existiert hat. Bei der Suche würden also alle Monumente ausgewählt, die in dem betreffenden Zeitraum existierten und deren Koordinaten innerhalb des angegebenen Polygons liegen.
Schließlich sei der Grafik-Server „Digilib“ erwähnt, der vom Max-Planck-Institut für Wissenschaftsgeschichte in Berlin und dem Institut für Wissenschaftsgeschichte der Universität Bern entwickelt und zum Teil an die Bedürfnisse der Bibliotheca Hertziana angepasst worden ist. Mit Digilib können hochaufgelöste, digitale Bilddateien schnell über das Netz abgerufen und vom Betrachter zur besseren Betrachtung vergrößert, gedreht und anderweitig manipuliert werden. Außerdem gibt es Annotationsfunktionen, mit denen man eigene Beobachtungen mitteilen kann, indem man einen URL zitiert. Der Aufruf dieser Adresse reproduziert den identischen, annotierten Ausschnitt des Bildes auf dem Zielrechner. So wird wissenschaftliche Kommunikation und Kommentierung von Bildern über das Internet erleichtert. Schließlich enthält Digilib noch eine Katalogfunktion, mit der komplett digitalisierte Manuskripte und seltene Bücher im Browser durchgeblättert werden können.
Datenformat
Trotz der ausführlichen Darstellung soll nicht der Eindruck entstehen, das Konzept von ZUCCARO bestünde primär in der Entwicklung einer neuen Software. Software veraltet, wie sich gezeigt hat, sehr schnell. Eine Datenbank ist nämlich nicht primär ein Computerprogramm, sondern eine Sammlung von Daten. Kunsthistorische Datensammlungen werden nicht selten über Generationen aufgebaut. Dabei kommt es in erster Linie darauf an, dass die wissenschaftlichen Angaben auch in fernerer Zukunft noch problemlos lesbar sind, und dass ihr innerer Zusammenhang bewahrt bleibt. Ebenso wichtig wie quelloffene Software ist daher ein nichtproprietäres, möglichst standardisiertes und nicht mit der Software aussterbendes Datenformat. Nur so kann langfristig die Nutzbarkeit der Daten gewährleistet werden. Daher ist muss man sich der Formatfrage mit besonderer Sorgfalt annehmen.
Während an dem Datenmodell bereits sehr detailliert gearbeitet wurde, herrschte über das Datenformat anfangs noch Unklarheit. Schnell wurde jedoch deutlich, dass hierfür nur ein modernes XML-Format in Frage kommen würde. Das ursprünglich als Auszeichnungssprache (extensible markup language) konzipierte Format ist in der Lage, sowohl hierarchisch organisierte als auch sich wiederholende Angaben und Angabengruppen abzubilden und Bezüge zwischen Datensätzen durch Referenzen auf eindeutige Schlüsselwerte (unique identifiers) herzustellen. Außerdem hat sich das XML-Format sein einigen Jahren durch die Empfehlungen des W3C-Konsortiums zu einem weltweit gültigen und gebräuchlichen Standard entwickelt. XML hat folgende Vorzüge:
- hierarchische, gruppierende und referenzierende Strukturierung
- Lesbarkeit auch ohne Entschlüsselung durch den Computer
- Wiedergabe internationaler Zeichensätze durch Unicode-Unterstützung
- Festlegung von Struktur und Datentypen in einem formalisierten Schema
- Automatische Überprüfbarkeit der Plausibilität der Daten anhand des Schemas
- zahlreiche Software und Programmmodule stehen zur Verfügung
Dem steht als einziger Nachteil der relativ große Speicherbedarf entgegen, der durch die Vielzahl und Redundanz der „tags“ hervorgerufen wird; er kann durch Komprimierung der XML-Dateien leicht ausgeglichen werden.
Wichtig ist vor allem, dass für die Langzeit-Speicherung und für den Datenaustausch (Import von bereits vorhandenen Daten, Export für die Archivierung und für anderweitige Verwendung des Materials) ein XML-Format verwendet wird. Die interne Verarbeitung der Daten muss nicht notwendigerweise in XML erfolgen. ZUCCARO erhält ein eigenes Import-Export-Format in XML, das in der Lage ist, die Besonderheiten des Datenmodells abzubilden, insbesondere das komplexe Beziehungssystem der Daten. Beim Import sind besondere Vorkehrungen notwendig, wenn Daten aus externer Quelle in das bereits bestehende Beziehungssystem eingebunden werden sollen. Hier sind zum Teil erhebliche Modifikationen der Quelldaten notwendig, um bereits bestehende Merkmal-Felder in Beziehungen aufzulösen und an vorhandene Datensätze anzubinden. Überlegungen hierzu sind derzeit noch im Gange.
Lizenz
Grundlegende Richtlinien für die Entwicklung von ZUCCARO sind die Grundsätze von Open Source und Open Access. Open Source bedeutet in diesem Fall nicht nur, dass das Institut mit dem lauffähigen Programm auch den Quellcode ausgehändigt bekommt. Der Programmtext wird vielmehr der Allgemeinheit zur Verfügung gestellt, und zwar unter der „Deutschen Freien Software Lizenz“ (d-fsl), die am Institut für Rechtsfragen der Freien und Open Source Software erarbeitet wurde. Das bedeutet zugleich auch, dass Verbesserungen von anderer Seite wiederum der Allgemeinheit und damit auch ZUCCARO zugute kommen.
Open Access versteht sich gemäß der “Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities”, die am 22. Oktober 2003 auch von der Max-Planck-Gesellschaft unterzeichnet wurde. Darin verpflichten sich die unterzeichnenden Institutionen, jedermann freien Zugang zu den Forschungsergebnissen und zu der dazu notwendigen Software zu gewähren. „Content and software tools must be openly accessible and compatible”, heißt es in dem Dokument. Mit öffentlichen Mitteln geförderte Projekte müssen auch öffentlich zugänglich sein. Diesem Grundsatz ist auch das Projekt ZUCCARO verpflichtet.
Anmerkungen und Links
- OPAC der Bibliothek: http://www.biblhertz.it.
- allegro/avanti: http://www.allegro-c.de/index.htm.
- Foto Marburg: http://www.fotomarburg.de/.
- Bildindex: http://www.bildindex.de/.
- Census: http://www.census.de/.
- Lineamenta: http://lineamenta.biblhertz.it/.
- HIDA: http://www.startext.de/produkte/hida/.
- MIDAS: Bove, Jens/Heusinger, Lutz/Kailus, Angela: Marburger Informations-, Dokumentations- und Administrations-System (MIDAS). Hrsg. vom Bildarchiv Foto Marburg, Deutsches Dokumentationszentrum für Kunstgeschichte, Philipps-Universität Marburg. 4. Auflage München 2001.
- Kleio: http://www.hki.uni-koeln.de/kleio/.
- Prometheus: http://www.prometheus-bildarchiv.de/.
- Getty Guidelines: http://www.getty.edu/research/conducting_research/standards/fda/.
- CIDOC: "http://www.cidoc.icom.org/", http://www.cidoc.icom.org/.
- CIDOC-CRM: "http://cidoc.ics.forth.gr/", http://cidoc.ics.forth.gr/.
- WIRE: Raspe, Martin: WIRE – An Instrument for Collecting Visual and Textual Data. In: Standards und Methoden der Volltextdigitalisierung. Beiträge des Internationalen Kolloquiums an der Universität Trier, 8./9. Oktober 2001 (Abhandlungen der Akademie der Wissenschaften und der Literatur, Mainz; Geistes- und sozialwissenschaftliche Klasse, Nr. 9), Stuttgart 2003, 317-322.
- OWL: http://de.wikipedia.org/wiki/Web_Ontology_Language
- Neo4j: http://www.neo4j.org/
- Thaller, Manfred: Bemerkungen zu kunsthistorischen Informationssystemen; vornehmlich aus der Sicht der Informatik. zeitenblicke 2 (2003), Nr. 1. http://www.zeitenblicke.historicum.net/2003/01/thaller/index.html.
- CIPRO: http://fmdb.biblhertz.it/cipro/.
- Digilib: http://digilib.berlios.de/.
- W3C: http://www.w3.org/XML/.
- Institut für Rechtsfragen der Freien und Open Source Software: http://www.ifross.de.
- Deutsche Freie Software Lizenz: http://www.ifross.de.
- Berlin Declaration: http://www.zim.mpg.de/openaccess-berlin/berlindeclaration.html.